En la clase anterior, nos planteamos un primer intento para la clasificacion de triadas.
En esta pagina, planteamos una prespectiva mas refinada del problema.
Comenzamos considerando
import numpy as np
# Original data
B = [1, 2, 3, 2, 3, 1, 3, 1, 2, 3, 1, 2, 1, 2, 3, 2, 3, 1, 3, 1, 2]
# Initialize renglon counter
renglon = 1
triada=[] # Declaramos la existencia de una lista
# Loop through the list in steps of 3
for rana in range(0, len(B), 3):
# Extract the current triplet
triada = np.array([B[rana], B[rana+1], B[rana+2]])
# Print the details
print('renglon', renglon, 'con la triada', triada, '---> rana=', rana)
# Increment renglon counter
renglon += 1
La cual produce una salida de la forma
englon 1 con la triada [1 2 3] ---> rana= 0 renglon 2 con la triada [2 3 1] ---> rana= 3 renglon 3 con la triada [3 1 2] ---> rana= 6 renglon 4 con la triada [3 1 2] ---> rana= 9 renglon 5 con la triada [1 2 3] ---> rana= 12 renglon 6 con la triada [2 3 1] ---> rana= 15 renglon 7 con la triada [3 1 2] ---> rana= 18
La instruccion len(B) nos da el numero de elementos
print(len(B)) 21
Considere el programa
import numpy as np # Datos originales B = [1, 2, 3, 2, 3, 1, 3, 1, 2, 3, 1, 2, 1, 2, 3, 2, 3, 1, 3, 1, 2] # Crear una lista para almacenar las triadas triada = [] triadas = [] # Iterar por la lista en pasos de 3 for rana in range(0, len(B), 3): triada = (B[rana], B[rana+1], B[rana+2]) # Usar tuplas para facilitar la comparación triadas.append(triada)
observe lo que realiza el programa
triada (3, 1, 2) triadas [(1, 2, 3), (2, 3, 1), (3, 1, 2), (3, 1, 2), (1, 2, 3), (2, 3, 1), (3, 1, 2)]
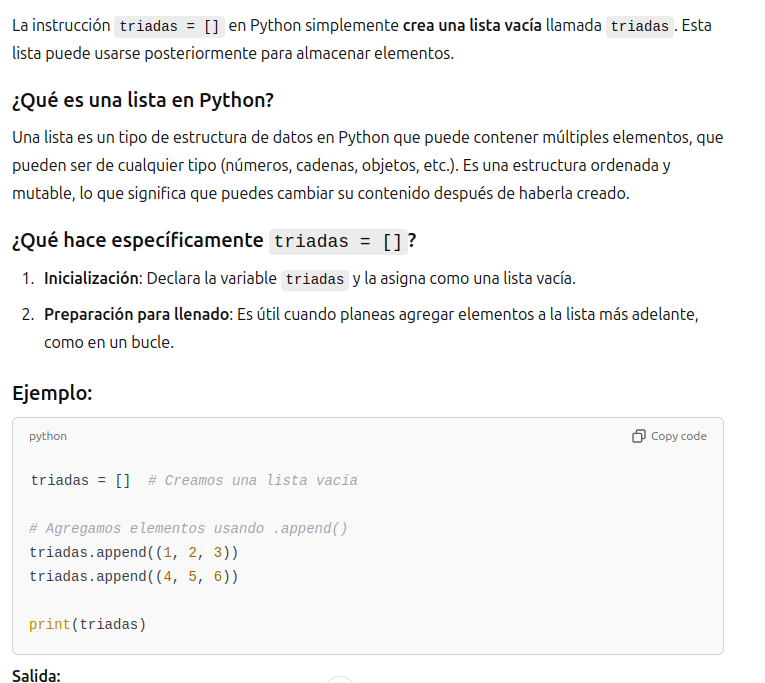
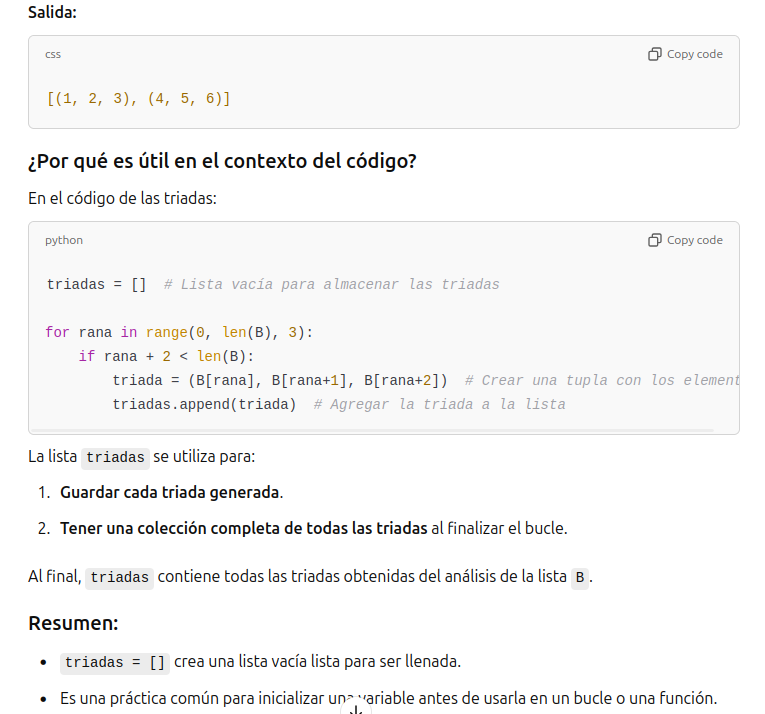
Hemos hecho una nueva lista que se llama triadas, que organiza los datos en triadas. Cada triada es un objeto de la lista. Existe una instruccion en python que Puede encontrar los elementos diferentes de una lista
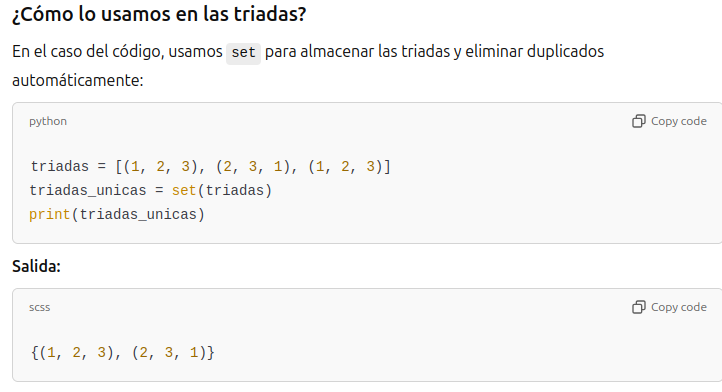
triadas_unicas = set(triadas)
print(triadas_unicas)
{(3, 1, 2), (2, 3, 1), (1, 2, 3)}
La instruccion set permite encontrar los elementos distintos. ?Que hace la instruccion set?
La instrucción set en Python crea un conjunto, que es una colección de elementos únicos y no ordenados. Su principal función es eliminar duplicados y permitir operaciones como unión, intersección y diferencia de conjuntos.
Propiedades de un conjunto (set):
- Únicos: No pueden existir elementos duplicados.
- No ordenados: No garantiza el orden de los elementos al almacenarlos.
¿Cómo funciona set?
Cuando pasas una lista, tuplas u otra colección a set, este automáticamente filtra y conserva solo los elementos únicos.
Ejemplos prácticos
1. Eliminar duplicados de una lista:
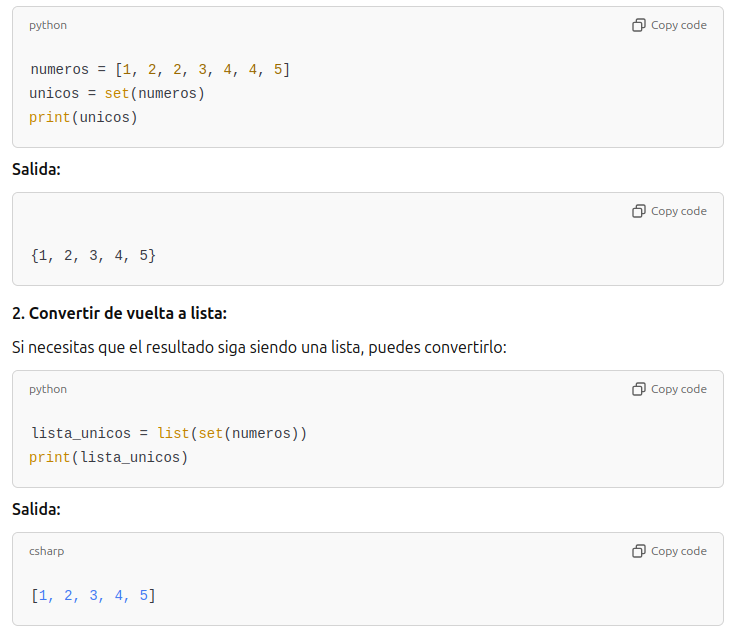
print(triadas_unicas)
print("Triadas únicas:")
for triada in triadas_unicas:
print(triada)
print("\nNúmero total de triadas únicas:", len(triadas_unicas))
Selection deleted
print(triadas_unicas)
print("Triadas únicas:")
for triada in triadas_unicas:
print(triada)
print("\nNúmero total de triadas únicas:", len(triadas_unicas))
{(3, 1, 2), (2, 3, 1), (1, 2, 3)}
Triadas únicas:
(3, 1, 2)
(2, 3, 1)
(1, 2, 3)
Número total de triadas únicas: 3
import numpy as np
# Datos originales
B = [1, 2, 3, 2, 3, 1, 3, 1, 2, 3, 1, 2, 1, 2, 3, 2, 3, 1, 3, 1, 2]
# Crear una lista para almacenar las triadas
triadas = []
# Iterar por la lista en pasos de 3
for rana in range(0, len(B), 3):
triada = (B[rana], B[rana+1], B[rana+2]) # Usar tuplas para facilitar la comparación
triadas.append(triada)
# Identificar las triadas únicas
triadas_unicas = set(triadas)
# Mostrar los resultados
print("Triadas únicas:")
for triada in triadas_unicas:
print(triada)
print("\nNúmero total de triadas únicas:", len(triadas_unicas))